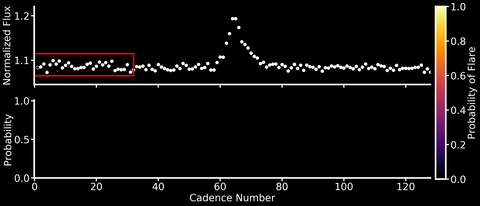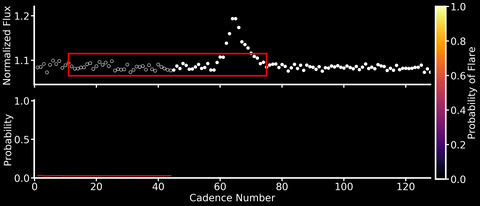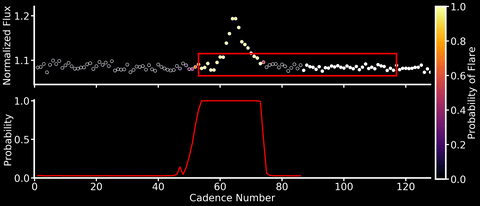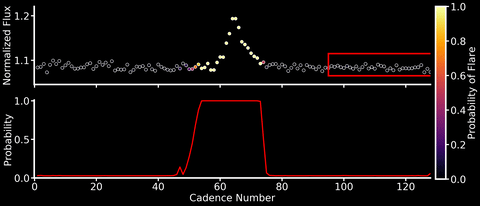
This will be both my first and last post to this blog after a short (but wonderful!) 6 months at the Flatiron Institute. So I wanted to share a machine learning project that I’ve been working over the past few months with Adina Feinstein, a PhD student at University of Chicago who many of you TESS users may already know from her Eleanor package. We’ve designed a Convolutional Neural Network (CNN) named Stella that automatically and rapidly detects flares in TESS light curves at high (99%!) precision and with minimal data preprocessing (no detrending of stellar activity signals needed!).
Neural networks are able to learn features directly from the data rather than having them hand-engineered by mere humans. CNNs are a specific type of neural network that are especially good at identifying spatial features in the data – a good thing if you’re looking for flares, which have a characteristic sharp rise and slow decline in light curves. We trained Stella on the flares identified in Gunther et al. 2020, and because the dataset was relatively small, this could be done on a laptop in about 30 minutes (no GPUs needed!). After training, Stella is able to obtain high precision (99%) and accuracy (98%) when identifying whether part of a TESS light curve contains a flare.
As shown in the animation above, we can then feed TESS light curves into this CNN “classifier” to transform it into a “detector” that outputs a sort of “flare probability time series” (where we use the term “probability” very, very loosely). Stella is also fast – it takes roughly 30 minutes to search 3500 TESS light curves for flares.
Keep an eye out for the paper presenting Stella and its application to some cool science cases in the coming months. As for now, feel free to check out the code on Github and send us any feedback (if you’re lucky you may get one of the sweet stickers we made with the Stella logo designed by Adina).
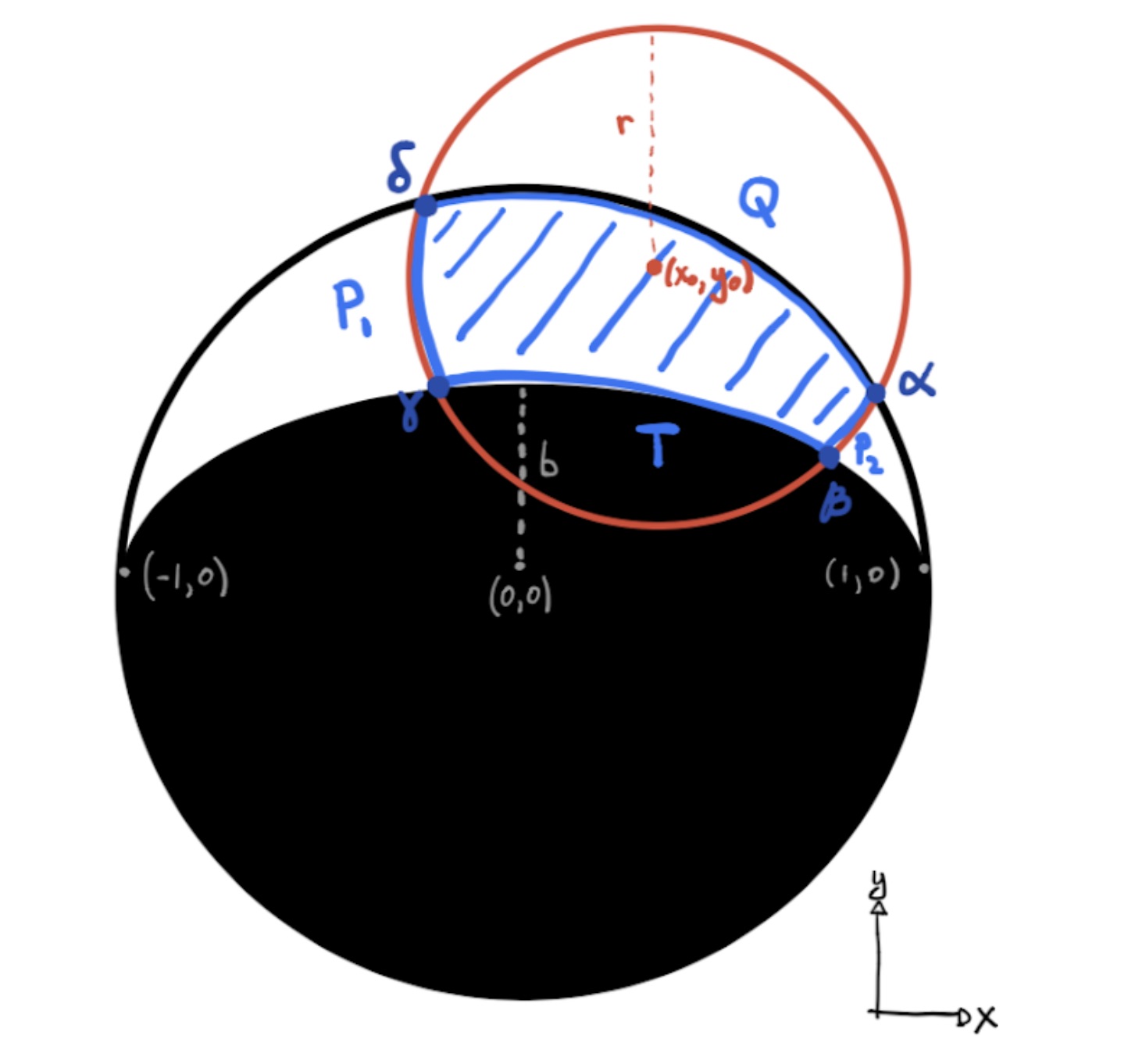
 As a new Flatiron Research Fellow who stared a few weeks ago, most of my time here so far has been taken up with getting myself set up in a new institute, and a new country. But, I’ve also had time to continue some of my thesis work from a few years ago now, which involves using the Made-to-Measure (M2M;
As a new Flatiron Research Fellow who stared a few weeks ago, most of my time here so far has been taken up with getting myself set up in a new institute, and a new country. But, I’ve also had time to continue some of my thesis work from a few years ago now, which involves using the Made-to-Measure (M2M; 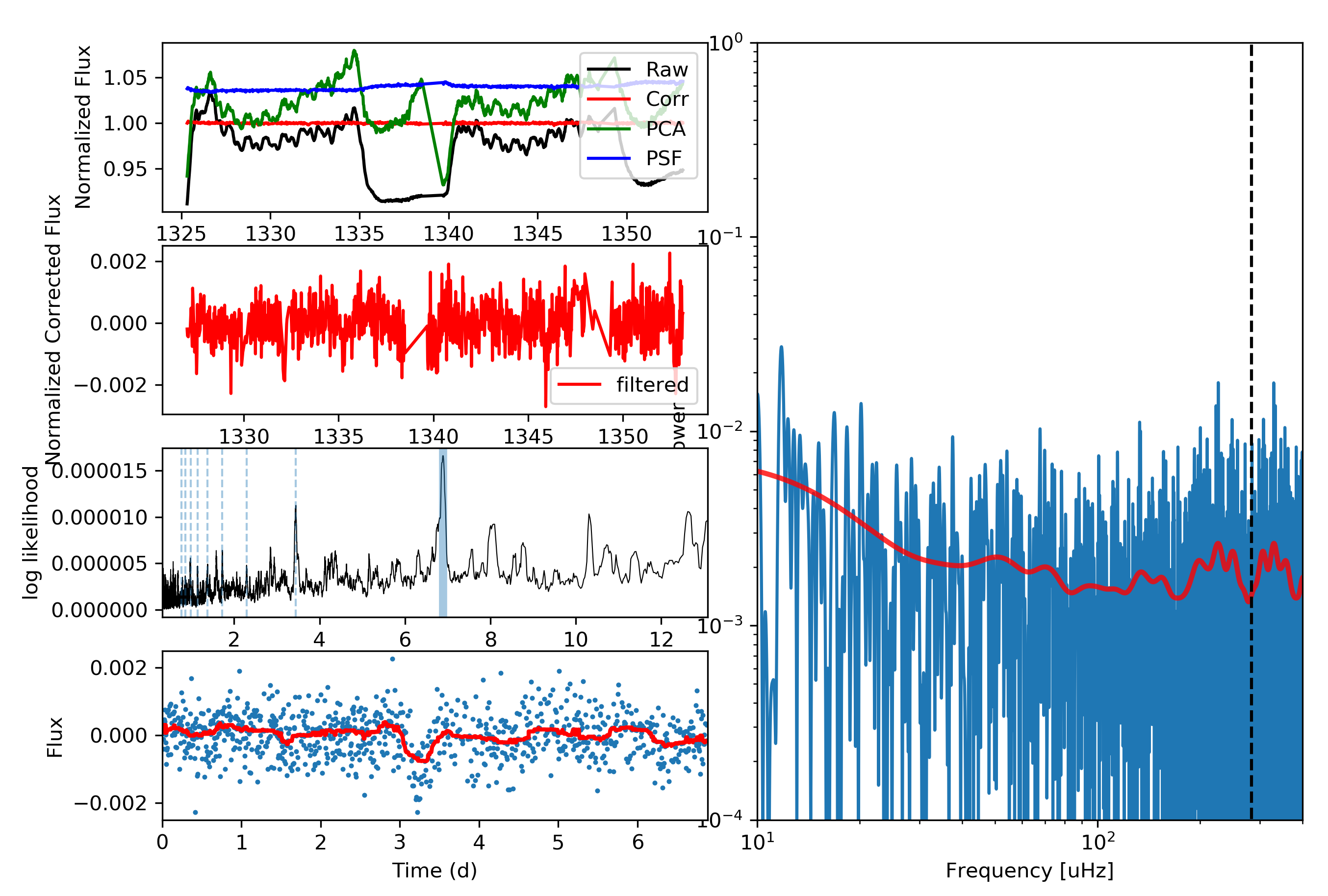
{kind=link}