At AstroHackWeek 2020 last week, a fight broke out - not between the supportive and friendly participants, but between emulators. I pitched a hack project on comparing emulation methods, mostly so I could show this emu vs. kangaroo fight video during my pitch, and a team of fighters assembled. All credit for this project shared with Catarina Alves, Johannes Heyl, Yssa Camacho-Neves, and Johnny Esteves!
{kind=link}
One of my research projects is on emulating galaxy clustering statistics for speedier, more accurate inference of cosmological and assembly bias parameters. I had been wanting to try out different emulation methods on this data, as well as write up a pedagogical tutorial on emulation. In brief, emulators are regressors that imitate more complex models or simulations. They are trained on a limited set of simulation inputs and output and learn the layout of this (often high-dimensional) parameter space; then for any new set of inputs, they can quickly spit out output values, without performing a physical calculation or a full simulation.
Our hack team first wrote up a detailed explanation of emulators, complete with an example about a computational emu biologist; check it out in our complete tutorial here. Then we wanted to actually build some emulators and test them on astronomical data. My full-scale research dataset proved unwieldy for a week-long project, so I generated a set of two-point correlation functions using nbodykit. The winning emulator should be able to take the input values of (Omega_m, sigma_8, Omega_b) and predict the correlation function in each of 10 separation bins.
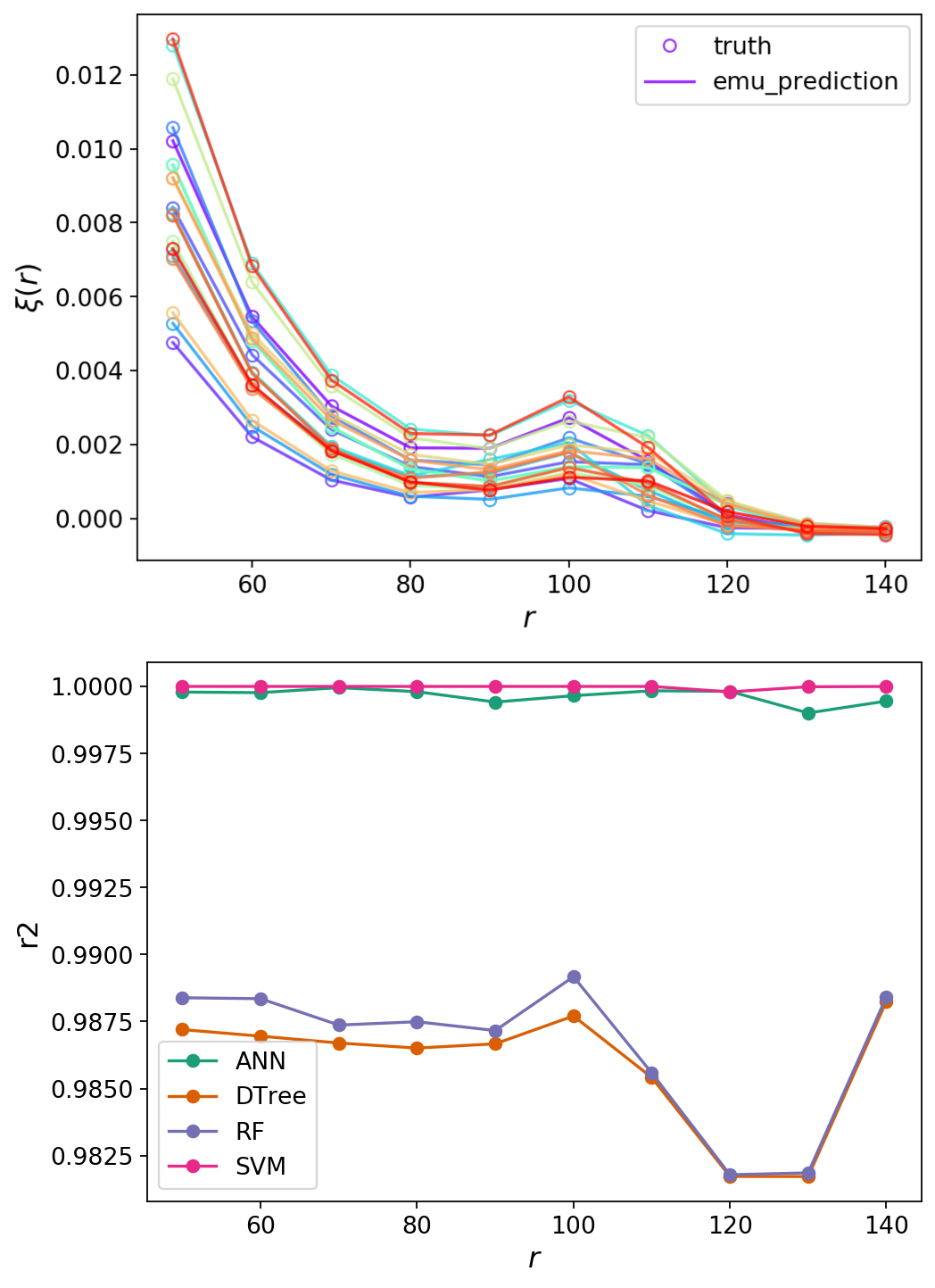
Each team member took on a different emulation framework. So far, our lineup includes an Artifical Neural Network, a Random Forest, a Decision Tree, and a Support Vector Machine (with Gaussian Processes on the way). The fighters tuned their implementations and hyperparameters to the best of their abilities. The fight was heated, with the emulators racing to train and test out their clustering predictions. You can see the predictions of the SVM compared to the true correlation function in the figure above.
To see the outcome, you’ll have to follow the full battle at The Great Emu Fight notebook. But the takeaways were:
- The Support Vector Machine emerged as the clear winner in accuracy for every metric we tested, emulating the correlation function to within a tenth of a percent for most r-bins. The Artificial Neural network came in a close second. (The second figure above shows the R^2 error; you can see the large difference in accuracy between the SVM and ANN compared to the DTree and RF.)
- However, the SVM was by far the slowest to train. The Decision Tree handily won the training round.
- The Decision Tree and the ANN were the winners when it came to prediction time (this is super important for inference!).
- The Random Forest was an all-around loser, being very slow at prediction and sadly inaccurate; we love and appreciate it anyway.
- Most importantly, all of these results are super dependent on emulator implementation, hyperparameter tuning, data normalization, and the dataset itself! So the reigning champion likely won’t reign for long.
- We built this project to be incredibly modular, so you can throw your own emulator or dataset into the ring. Follow one of our standalone notebook tutorials and tune the hyperparameters to improve on our results, or add in your own complete implementation, and join in the fight.
Check out the project in this repo, and follow the complete fight at The Great Emu Fight notebook. Huge thank you to the emu-fight team and the AstroHackWeek organizers!