Jiayin Dong (DJ) updated us on her project to study the eccentricity distribution of warm-Neptune exoplanets discovered using data from the TESS mission. She has discovered and carefully characterized about 100 of these transiting planets. She then uses the “photoeccetric effect” to infer the distribution of eccentricities based on the observed distribution of effective “circular stellar densities”. The inferred distribution is the observed population of orbital eccentricities but, if the detectability of the planet is correlated with eccentricity, this won’t necessarily be equivalent to measuring the true intrinsic eccentricity distribution. This will be an important effect (eccentricity will scale with orbital period and the probability that a planet transits is also a function of its eccentricity), so DJ asked the group for recommendations about how to take this into account. This led to a discussion about “inverse detection efficiency” methods versus likelihood-based methods for population inference. (I have opinions about this… I’m writing this post so I’m allowed to editorialize!)
Next, John Forbes shared a data analysis challenge where he has a simulation of a forming galaxy where he has snapshots of several quantities that, to order of magnitude, should sum to satisfy a differential equation. In practice, because of numerics and approximations this differential equation is not exactly satisfied, so he is interested in fitting for, possibly time and space invariant, offsets or scales for each of these quantities to best fit the constraints. Currently, he is using linear least squares to fit for multiplicative factors (that don’t depend on time or position) for each quantity, but finds that the results are not satisfactory. Several suggestions were made for relaxing these assumptions and fitting a more flexible model. One option would be to fit multiple galaxies together (in some sort of hierarchical model) to propagate information between them. Another would be to allow use a Gaussian Process either to model residuals away from the least squares model or as priors on the coefficients that enforce smoothness in time and space.
Then, Daivd W. Hogg shared a first draft of a Mission Statement and 5-Year Plan for the Astronomical Data Group. These highlight some of the things that we think we do well (encourage better data analysis practices, develop and support open source software, etc.), but also identify some of the places where we want to spend more energy. The goal is to use these documents to help focus research areas and other group efforts, as well as hiring decisions.
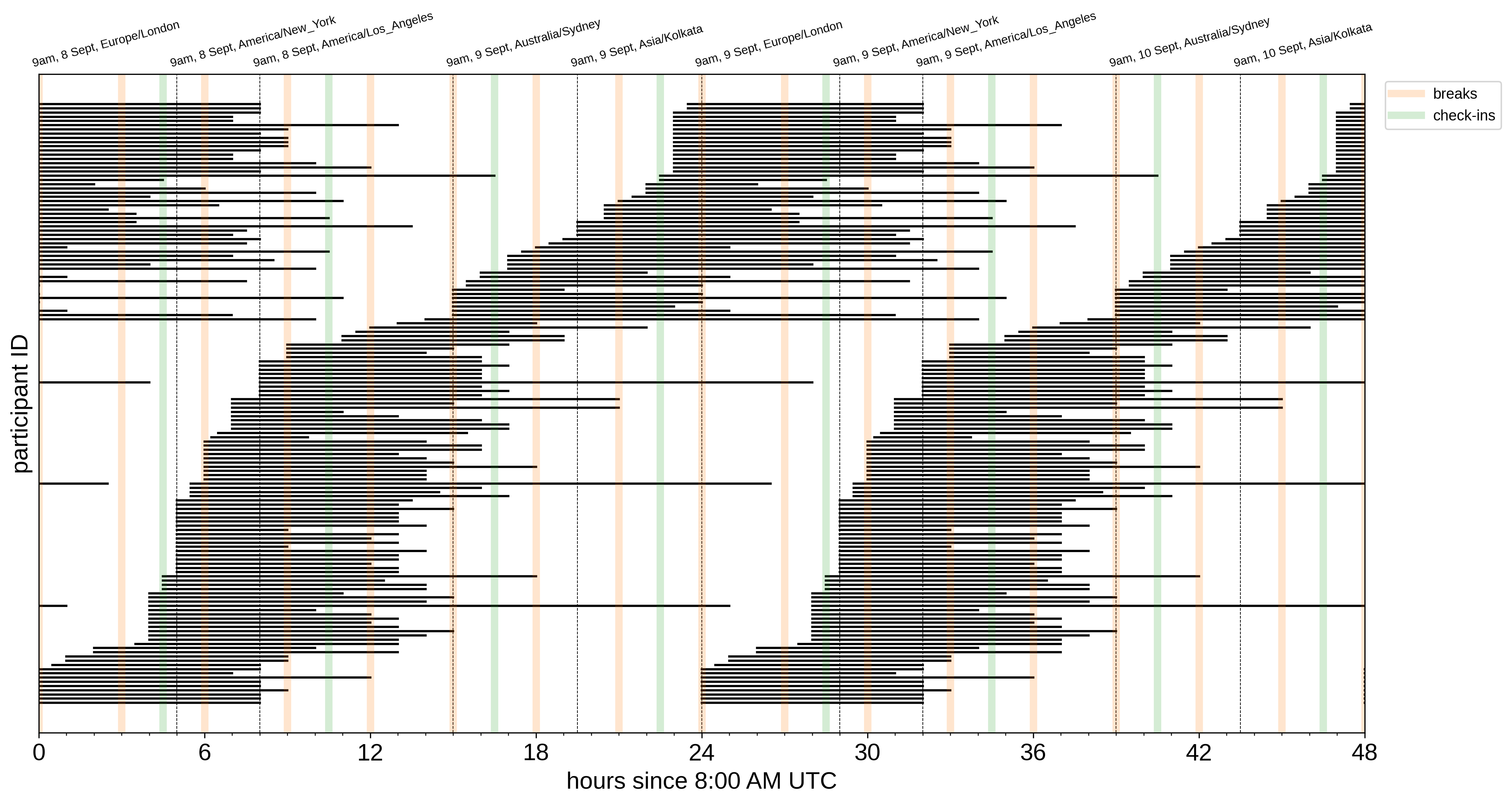
Finally, I gave an update on the online.tess.science event (hackathon/sprint/something) that I am co-organizing. It starts on Sept 8 (just over one week from now!) and there will be nearly 150 participants from around the world. The header figure for this post shows the times that each participant is planning on being online during the 48 hours of the event - this really is a global experiment! We are working to find the right balance of unstructured, asynchronous time and synchronous social/networking/check-in time with the goal of encouraging participants to meet a broad range of other community members. Much of this, as well as our recommendations for how to navigate an event like this, is being codified in a “Participant Handbook” that I’ve drafted with my co-organizers. I expect that this document will continue to be useful for future events, even if they are in-person.